1
Create a check
Tell the service when a task should report in and how much slack it gets.
Monitor scheduled jobs, workers, backups, and automation with one lightweight heartbeat. When something goes quiet, drifts late, or breaks, you see it fast.
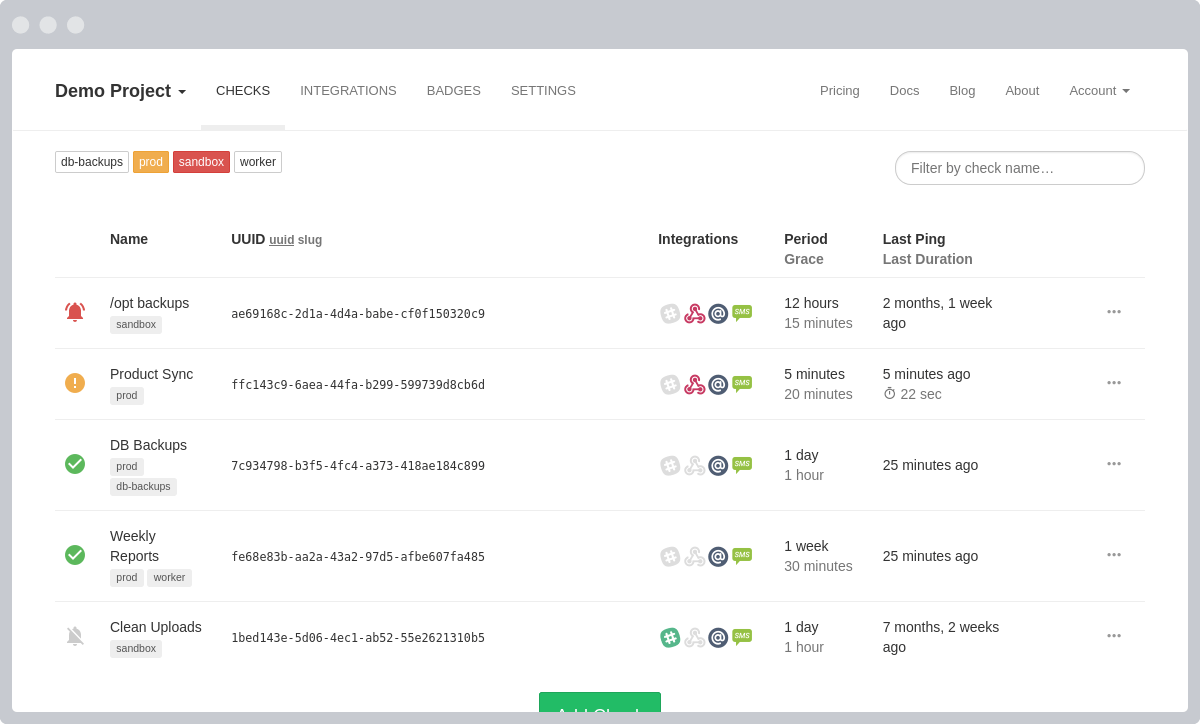
See what is up, late, down, or newly failing from one clean list.
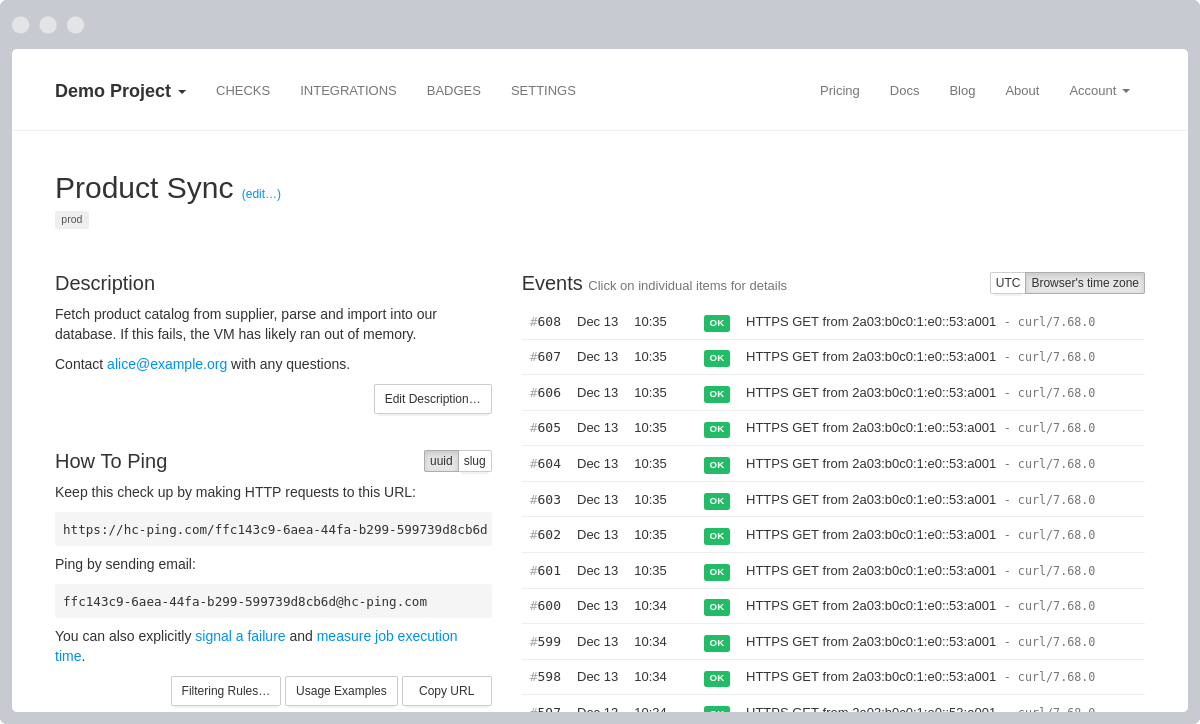
Inspect individual jobs, recent events, and failure history without leaving the dashboard.
Tell the service when a task should report in and how much slack it gets.
Call the generated URL from cron, a worker, or any scheduled command after it finishes.
If a run disappears, arrives late, or keeps failing, the service escalates immediately.
The scope is intentionally narrow: monitor scheduled work, verify it still runs, and give operators a clean surface for seeing what is late, down, or recovering.
Catch tasks that still run, but drift beyond the window your system can tolerate.
Track database dumps, snapshot exports, archive rotation, and cross-region syncs.
Use ping URLs for queue consumers, reconciliation jobs, and periodic maintenance tasks.
No heavy agent. Add a curl command, leave the job where it already lives, and move on.
Add one ping URL to the end of a script or scheduled command. When the ping stops arriving, the service treats silence as failure and alerts you.
Attach the ping URL after a successful run so skipped executions show up immediately.
0 * * * * /srv/jobs/nightly-report.sh && curl -fsS https://hc.bestboy.work/ping/your-uuid
Call the endpoint periodically from a long-running background process to prove it is still alive.
while true; do ./worker --sync-once && curl -fsS https://hc.bestboy.work/ping/your-uuid; sleep 60; done